Immersive Viewer Experiences with Light Field Imaging
Light field imaging is a promising technology that will provide a more immersive viewing experience. It enables some post-processing tasks like depth estimation, changing the viewport, refocusing, etc. To this end, a huge amount of data needs to be collected, processed, stored, and transmitted, which leaves the challenging task of compression and transmission of light field images [1]. Unlike conventional photography that integrates the rays from all directions into a pixel, light field imaging collects the rays from all directions resulting in a multiview representation of the scene. An example of a multiview representation of a light field image is shown in Fig 1 below and in an interactive format here:

In this post, we introduce a novel light field coding solution, namely, Scalable Light field Coding (SLFC), which addresses the above-mentioned functionalities in addition to the encoding efficiency.
Functionalities of Light field Coding
Aside from the baseline function of reducing redundancies by collecting and comparing images from multiple views, the complexity of Light field Coding is affected by four key factors:
- Viewport scalability: Unlike conventional 2D displayed images (and media in general), light field image coding solutions require that all views are encoded, transmitted, and decoded to alleviate high dependency between views, thereby enabling more arbitrary views (such as the standard 2D central view). Contrarily, conventional 2D displays only display a central view, which by comparison, is a significantly less immersive experience. The scalability limitation of these multi-viewports is that in order to increase the compatibility of Light field Coding solutions with capturing devices, displays, network condition, processing power, and storage capacity, viewports must be grouped into different layers [3] and so that they can be encoded, transmitted, decoded, and displayed one after another, a significantly more complex task than conventional coding.
- Quality scalability: To increase compatibility with the network condition and processing power, light field images can be provided in two (or more) quality levels. With the increasing available bandwidth and/or power, the quality of light field images can be improved by transmitting the remaining layers.
- Viewport random access: To avoid decoding delay, high bandwidth requirement, and huge processing power while navigating between various viewports, random access (the number of views required to access a specific view) to the image views should be considered in light field image coding.
- Uniform quality distribution: To avoid facing quality fluctuation when navigating between viewports, light field image views should have similar qualities at each bitrate.
Introducing SLFC: Scalable Light Field Coding
To address the additional complexities that come with standard Light field Coding, we propose the Scalable Light Field Coding (SLFC) solution. The first function that SLFC addresses are the viewport scalability issue by dividing multiviews into seven layers and encoding them for efficiency.

In each layer, views represented by red belong to that layer, while gray views belong to the previous layers, and black views belong to the next layers. To provide compatibility with 2D displays, the first layer contains the central view. The second layer contains the four corner views. For the remaining layers, available horizontal and vertical intermediate views are added.
Encoding the views
The process of encoding each layer is a three-step process that’s defined by the horizontal and vertical differences between each layer/view:
- Firstly, the central view (the first layer) is independently intra-coded, primarily defined by the red central dot.
- The second step takes the views from the second layer and is encoded independently of each other while using the central view as their reference image.
- The remaining layers are made of horizontal and vertical intermediate views of previously encoded views. For example in layer 3, four possible horizontal and vertical intermediate views are added. In each layer (3 to 7), two views from the previously encoded layers are used to synthesize their intermediate view. Sepconv [4] which has been designed for video interpolation is used for view synthesis. You can see an example of this process in the image below:
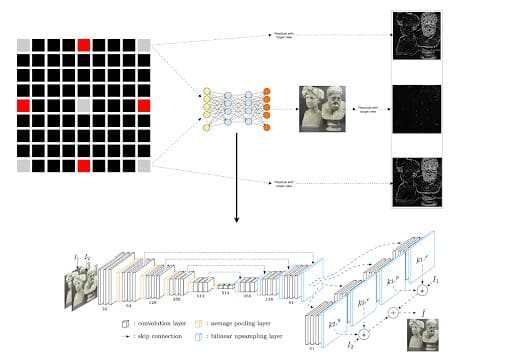
In the example above, the layers are synthesized from the top-right and bottom-right views to create the most accurate representation of the multiview approach. As a result, the synthesized view has less residual data compared to the individual top-right and bottom-right views. Therefore, this synthesized view is added to the reference list in the video encoder as a virtual reference frame. All-in-all, four reference views are used for encoding each view in layers 3 to 7: (i) the most central view, (ii, iii) two views that are used for synthesizing the virtual reference frame, (v) and the synthesized view.
Experimental results of Applied SLFC
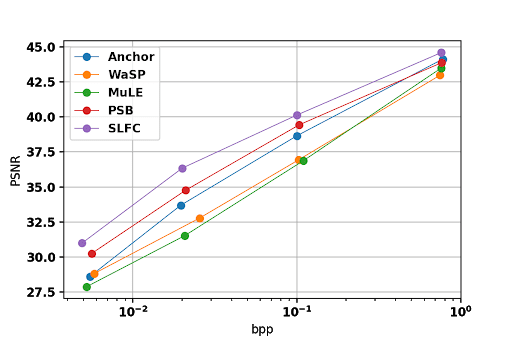
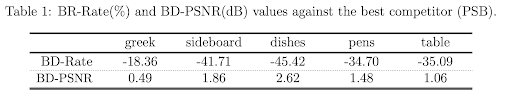
Encoding efficiency: Encoding efficiency of Table light field test image [5], compared to JPEG Pleno anchor [6], WaSP [7], MuLE [8], and PSB [9] is shown in Fig. 4. BD-Rate and BD-PSNR for other test images against the best competitor (PSB) are given in Table. 1.
Scalability: the number of views inside each layer, and allocated bitrate to each layer at bpp=0.75 for different layers are shown in Fig. 5.

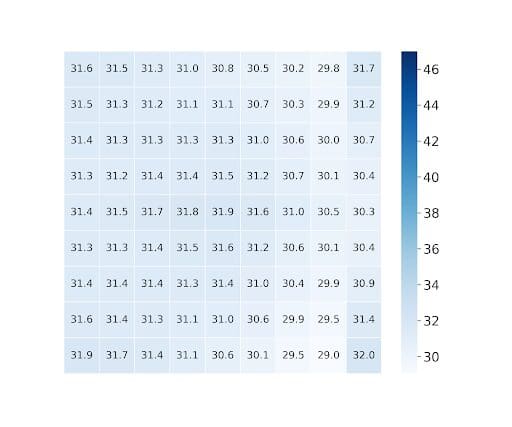
Random Access: The required bitrate to access each view at bpp = 0.75 for Table test image is shown in Fig. 6.
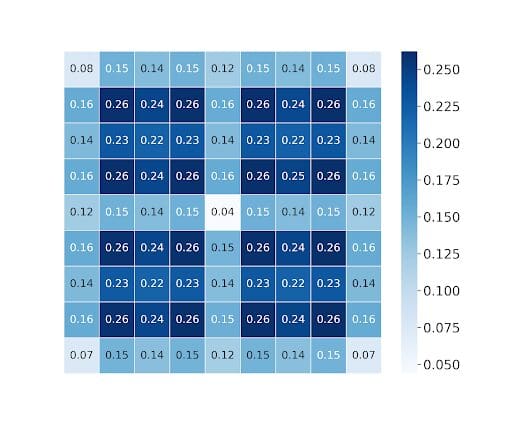
ScalabQuality Scalability: The synthesized view is considered as quality layer 1 and utilizing the synthesized view for inter-coding results in quality layer 2.
Quality Distribution: PSNR heatmap plot for Table light field images bpp = 0.005 is shown in Fig. 7.
Conclusion
The study of Scalable Light Field Coding (SLFC) was enacted in an attempt to optimize the process of “standard” light field coding by improving the applied compression. Our methodology added multiple critical compression features, such as viewport scalability (how many views are delivered), quality scalability, random access, and uniform quality distribution (wherein there are very few differences in quality between different views). The results of our research were that the SFLC method improves the quality of experience (QoE) for multiview content by a significant margin. In the future, applying SLFC to video and image workflows will help create a more immersive and higher-quality VR/AR experience. Conceivably allowing consumers to truly feel like they are within the environment that they are simulating.
Check out our full study and more at the following link here
- [PDF] Full study
- Slidedeck
- Presentation
Sources:
[1] C. Conti, L. D. Soares, and P. Nunes, “Dense Light Field Coding: A Survey,” in IEEE Access, vol. 8, pp. 49244-49284, 2020, DOI: 10.1109/ACCESS.2020.2977767.
[2] G. Wu et al., “Light Field Image Processing: An Overview,” in IEEE Journal of Selected Topics in Signal Processing, vol. 11, no. 7, pp. 926-954, Oct. 2017, DOI: 10.1109/JSTSP.2017.2747126.
[3] Ricardo Jorge Santos Monteiro, “Scalable light field representation and coding,” 2020.
[4] S. Niklaus, L. Mai, and F. Liu, “Video Frame Interpolation via Adaptive Separable Convolution,” 2017 IEEE International Conference on Computer Vision (ICCV), Venice, 2017, pp. 261-270, DOI: 10.1109/ICCV.2017.37.
[5] Katrin Honauer, Ole Johannsen, Daniel Kondermann, and Bastian Goldluecke, “A dataset and evaluation methodology for depth estimation on 4D light fields,” in Computer Vision – ACCV 2016, Shang-Hong Lai, Vincent Lepetit, Ko Nishino, and Yoichi Sato, Eds., Cham, 2017, pp. 19–34, Springer International Publishing.
[6] F Pereira, C Pagliari, EAB da Silva, I Tabus, H Amirpour, M Bernardo, and A Pinheiro, “JPEG pleno light field coding common test conditions v3. 2,” Doc. ISO/IEC JTC, vol. 1.
[7] P. Astola and I. Tabus, “Wasp: Hierarchical warping, merging, and sparse prediction for light field image compression,” in The 7th European Workshop on Visual Information Processing (EUVIP), Oct 2018, pp. 435–439.
[8] M. B. de Carvalho, M. P. Pereira, G. Alves, E. A. B. da Silva, C. L. Pagliari, F. Pereira, and V. Testoni, “A 4D DCT-Based lenslet light field codec,” in 2018 25th IEEE International Conference on Image Processing (ICIP), Oct 2018, pp. 435–439.
[9] L. Li, Z. Li, B. Li, D. Liu, and H. Li, “Pseudo-Sequence-Based 2-D Hierarchical Coding Structure for Light-Field Image Compression,” in 2017 Data Compression Conference (DCC), April 2017, pp. 131–140.