

Introduction
One of the main benefits of using a cloud-based SaaS product is the freedom to experiment, pivot and react to changes in your business without the overhead cost and time of buying and maintaining your own systems. The cloud lets you adjust on the fly and can scale infinitely and on-demand to meet your requirements…right? That expectation means creators of SaaS products like Bitmovin need to be able to react without warning to changing customer needs. Scaling up is an ongoing challenge of optimizing internal systems while bound by the real-world limitations of cloud infrastructure providers. Overcoming one obstacle often results in a new one presenting itself, so the work on improving scalability is never done.
Over the past year, we were fortunate to see a large increase in the volume of encoding jobs processed by our system, which included one case where a customer submitted a batch of 200,000 files! Unexpected spikes like that can cause some stress, but they also help uncover the areas where a little improvement can go a long way toward taking your scale and stability to another level. This post will share the lessons we learned and improvements we’ve made in recent months to enable higher throughput and safe scaling through future spikes in demand.
Highlights of Recent Performance Improvements
Here are some of the highlights of our scalability work done since late last year:
- Average time for scheduling decisions dropped from 40 seconds to less than 2 seconds (under high load)
- 3x more efficient message processing in our API services
- 4x more efficient Encoding Start Calls, drastically reducing 504 timeouts
- Added tracing to core services, enabling continuous improvements and bottleneck reduction. So far, we’ve been able to decrease the total volume of database statements executed by a factor of 6 and the average statement size by a factor of 4, greatly improving our overall capacity and scalability.
- Implemented “Safe Scaleup” algorithm in our scheduler to safeguard the overall system from peaks in pressure if a customer(s) submits a large amount of encoding jobs in a short period of time
Keep reading for more detail about how we were able to make these improvements.
Speeding Up Scheduling Decisions
Customers of Bitmovin’s VOD Encoding service are effectively sharing the pooled resources of our cloud deployments and we have safeguards in place to ensure fair use of those shared resources. We also have a lot of monitoring and alerting in place to ensure everything is performing as efficiently as expected. After seeing longer than expected queuing times and underutilized encoding capacity, the team added time traces to the logs to investigate further. The root cause was identified as slow scheduling decisions, taking an average of 40 seconds with peaks of up to 4 minutes, prompting them to make these changes:
- Removed penalty for the number of finished encodings – Our fair scheduling algorithm took into account the number of recently completed encodings, which could impact a customer’s priority more than necessary. The team also saw the calculation took up to 20 seconds and didn’t provide a huge benefit, so they decided it was safe to remove.
- Status updates for encoding jobs were moved from sequential to batch processing.
- Change from UUID v4 to UUID v1 – Database task insertion was detected to be really slow and the team found inefficient updates caused by the random strings in UUID v4. MySQL is optimized for monotonically increasing keys, so changing to UUID v1 which has a time component and thus is monotonically increasing, proved to be much more efficient.
Together, those changes brought the average scheduling decision time from 40 seconds (under load) down to a constant 2 seconds, which was a pretty noticeable improvement.
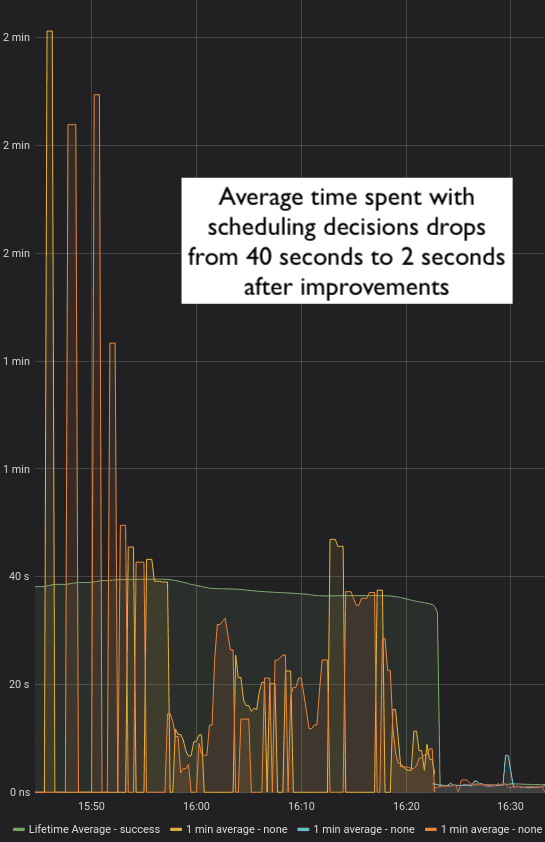
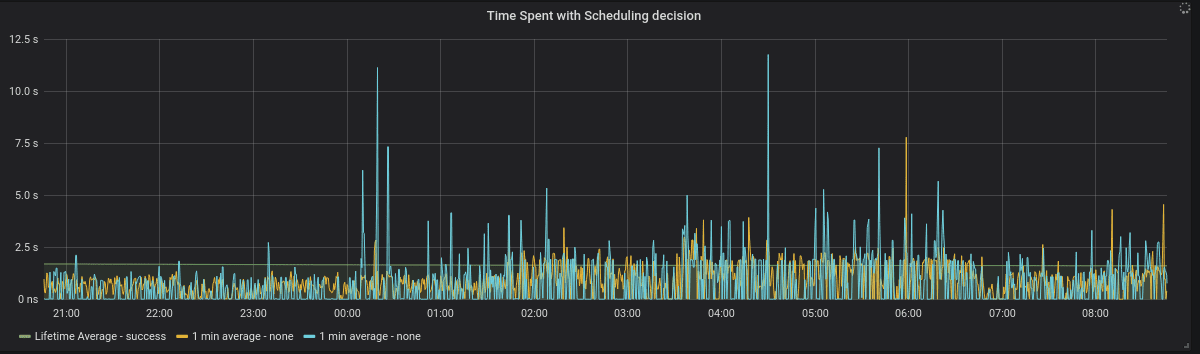
Looking closer at the timeline after improvements, we see the average decision time down to 2 seconds and even the worst-case outliers are under 12 seconds.
Increasing Message Throughput
We have several internal messaging services to coordinate tasks, one of which is responsible for processing the messages that track the status of encoding jobs, including the update that signals when a job is complete. Slow processing of those messages means the status is not set to FINISHED and gives the perception of much longer encoding times.
Our statistics service is responsible for collecting the statistical data of encoding jobs like the number of output minutes produced and general billing related tasks. During extremely high loads of encoding jobs, there are a LOT of messages that need to be processed. However, the team found that the high volume of messages, combined with optimistic locking exceptions on the database layer could lead to failures during message processing. All the subsequent retries would further strain the system and the throughput of successful messages processed would end up being fairly poor.
The team added additional metrics to analyze the root cause of the performance bottlenecks occurring under extreme loads. This analysis led to 3 main changes that highly improved the throughput of the message processing in both services:
- Use UUID v1 instead of UUID v2 as datatype for indexed columns
- Fix automatic dirty checking of Hibernate
- Optimization to skip unnecessary subtask updates
Reducing Timeouts of Encoding Start Calls
Especially for encoding jobs that have a big configuration (e.g., a lot of Streams, Muxings, etc.) we saw that the processing times of an Encoding Start call could sometimes take longer than 60 seconds. Our API gateway is configured with a 60 seconds timeout, thus our customers were getting 504 gateway timeout errors. Many customers did not have good retry mechanisms or strategies in place, so we shared this article that documents our best practices for handling 5xx errors.
When starting an encoding job the Bitmovin API services have to gather all configured data and combine them into a single configuration of the whole encoding. This is done synchronously so that we can validate if the setup of the encoding is correct and inform the customer immediately in case there is any misconfiguration. This is especially slow for encodings with lots of configured streams and muxings as a lot of information for each entity has to be retrieved from the database (for example Input Streams, Muxings, Filters, Sprites, Thumbnails, etc.). Additionally, some updates on the stream level are done before scheduling an encoding to ensure data consistency.
The team needed to add additional performance metrics to this call for an in-depth investigation of performance bottlenecks. This allowed us to find and fix problematic queries and update behaviors. The improvements implemented led to a reduction of the average Encoding Start call time by a factor of four. Additionally, the fix includes improved observability into the Encoding Start process to make further improvements possible.

Observability and Performance Improvements
Since the beginning of the year, the team has worked hard to enable tracing with OpenTelemetry to all of our core services. With it, all traces to inbound as well as outbound service calls are reported, including:
- Sync/async service calls
- Messaging and Events
- Resources
- Database
That provides a live cross-service performance factor which is important to identify performance bottlenecks in the whole workflow. Service-specific RED metrics are recorded to allow further investigations and optimizations. The team also added additional performance metrics to the critical parts of our core services. With those observability improvements, we were able to implement the following improvements to our overall encoding orchestration workflow, which has a huge impact on scalability:
- Reduced executed DB statement count by factor of 6
- Reduced DB statement size by factor of 4
- Reduced internal service calls by factor of 3
- Reduced complexity of internal calculations by factor of 2
The next steps will be to further add observability capabilities to our core encoding workflow that actually performs the encoding job. With that, we should be able to further tune the turnaround time of single encoding jobs as well.
Implementing Safe Scaleup for Higher Overall Throughput
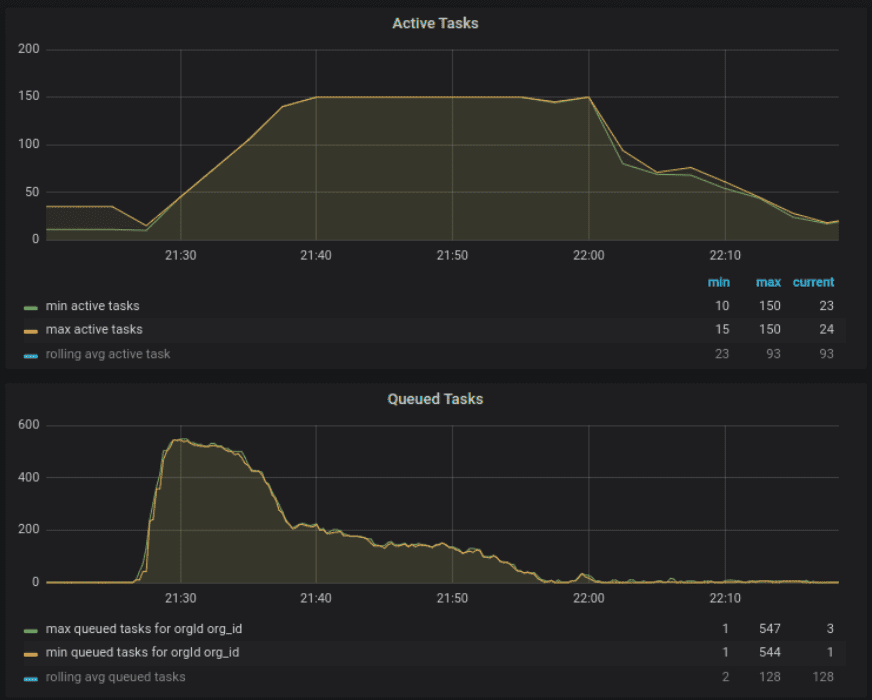
Our system is optimized to start encoding jobs as soon as possible once the customer has configured everything and executed the encoding start call. Some of our enterprise customers have as many as 200 encoding slots and we observed that when they filled all 200 slots in a very short amount of time, it was not only bringing our system (database, messaging, etc.) but also our cloud providers’ systems (where we request the required infrastructure) under high pressure. Those bursts of requesting infrastructure were often leading to “slow down” responses by the cloud providers’ APIs and “capacity exceeded” responses when acquiring infrastructure, as they can not provide that many instances in that short amount of time.
To avoid these bursts in processing, we now use a better strategy to safely ramp up the usage of the available encoding slots, leading to more normalized usage of our system as well as the infrastructure of our cloud providers. This ultimately means we’re able to support greater overall capacity since we’re requesting resources in a way that allows our infrastructure partners to keep up. In the bottom half of the graph below, we see the customer submitted almost 600 jobs in a short period of time. On the upper half, we see how the system now safely scales the usage up to their limit of 150 concurrent encoding jobs.
A Neverending Story
Being a best-in-class SaaS product means being able to meet your customers’ changing needs instantly, while managing the reality that your infrastructure providers and your own systems have limitations for scaling. Providing enterprise-level uptimes requires constant vigilance and adaptation to support even modest levels of growth, not to mention huge spikes in demand. It’s impossible to predict every scenario in advance, but by taking advantage of the opportunity to learn and build a more robust system, you can set a higher standard for stability that benefits everyone in the long run.