The Future of HTTP Adaptive Streaming (HAS)
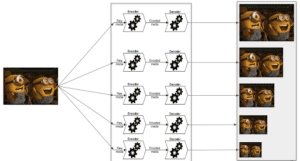
According to multiple reports, video viewing will account for as much as 82% of all internet traffic by the end of 2022, as such the popularity of HTTP Adaptive Streaming (HAS) is steadily increasing to efficiently support modern demand. Furthermore, improvements in video characteristics such as frame rate, resolution, and bit depth raise the need to develop a large-scale, highly efficient video encoding environment. This is even more crucial for DASH-based content provisioning as it requires encoding multiple representations of the same video content. Each video is encoded at multiple bitrates and spatial resolutions (i.e., representations) to adapt to the heterogeneity of network conditions, device characteristics, and end-user preferences as shown in Figure 1. However, encoding the same content at multiple representations requires substantial resources and costs for content providers.
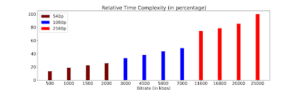
As seen in Figure 2, as resolution doubles, encoding time complexity also doubles! To address this challenge, we must employ multi-encoding schemes to accelerate the encoding process of multiple representations without impacting quality. This is achieved by exploiting a high correlation of encoder analysis decisions (like block partitioning and prediction mode decisions) across multiple representations.
What is Multi-Encoding?
To encode multiple renditions of the same video at multiple bitrates and resolution, we reuse encoder analysis information across various renditions. This is due to the fact that there is a strong correlation of encoder decisions across various bitrate and resolution renditions. The scheme of sharing analysis information across multiple bitrates within a resolution is termed “multi-rate encoding” while sharing the information across multiple resolutions is termed as “multi-resolution encoding”. “Multi-encoding” is a generalized term that combines both multi-rate and multi-resolution encoding schemes.
Proposed Heuristics:
To aid the encoding process of the dependent renditions in HEVC, the ATHENA Labs research team proposes a few new encoder decision heuristics, Prediction Mode and Motion Estimation:
Prediction Mode Heuristics:
Prediction Mode heuristics are those where the selected Coding Unit (CU) size for the dependent renditions is the same as the reference representation – this can be further broken down into the following modes:
- If the SKIP mode was chosen in the highest bitrate rendition, rate-distortion optimization is evaluated for only MERGE/SKIP modes.
- If the 2Nx2N mode was chosen in the highest bitrate rendition, RDO is skipped for AMP modes.
- If the inter-prediction mode was chosen in the highest bitrate rendition, RDO is skipped for intra-prediction modes.
- If the intra-prediction mode was chosen for the highest and lowest bitrate rendition, RDO is evaluated for only intra-prediction modes in the intermediate renditions.
Motion Estimation Heuristics:
Motion Estimation heuristics are those where the CU size and PU selected for the dependent representations are the same as the reference representation:
- The same reference frame is forced as that of the highest bitrate rendition.
- The Motion Vector Predictor (MVP) is set to be the Motion Vector (MV) of the highest bitrate rendition.
- The motion search range is decreased to a smaller window if the MVs of the highest and the lowest bitrate renditions are close to each other.
Based on the above-mentioned heuristics, two multi-encoding schemes are proposed.
Proposed Multi-encoding Schemes
In our first proposed multi-encoding approach we perform the following steps:
- The first resolution tier (i.e, 540p in our example) is encoded using the combination of double-bound for CU depth estimation (c.f. Previous blog post), Prediction Mode Heuristics, and Motion Estimation Heuristics.
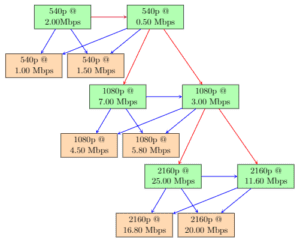
- The CU depth from the highest bit rate representation of the first resolution tier (i.e., 540p) is shared with the highest bit rate representation of the next resolution tier (i.e., 1080p in our example). In particular, the information is used as a lower bound, i.e., the CU is forced to split if the current encode depth is lower than the reference encode CU depth. The remaining bitrate representations of this resolution tier are encoded using the multi-rate scheme as used in Step 1.
- Repeat Step 2 for the remaining resolution tiers in ascending order with respect to the resolution until no more resolution tiers are left (i.e., only for 2160p in our example).
Figure 3: An example of the first proposed multi-encoding scheme.
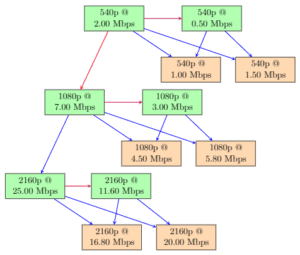
The second proposed multi-encoding scheme is a minor variation of the first scheme which aims to extend the double-bound for CU depth estimation scheme across resolution tiers. It is performed in the following steps:
- The first resolution tier (i.e., 540p in our example) is encoded using the combination of double-bound for CU depth estimation, Prediction Mode Heuristics, and Motion Estimation Heuristics.
- The CU depth from the lowest bit rate representation of the first resolution tier (i.e., 540p) is shared with the highest bit rate representation of the next resolution tier (i.e., 1080p in our example). In particular, the information is used as a lower bound, i.e., the CU is forced to split if the current encode depth is lower than the reference encode CU depth.
- The scaled CU depth from the lowest bit rate representation of the previous resolution tier (i.e., 540p) and CU depth information from the highest bit rate representation of the current resolution tier are shared with the lowest bit rate representation of the current resolution tier (i.e., 1080p in our example) and are used as the lower bound and upper bound respectively for CU depth search.
- The remaining bit rate representations of this resolution tier (i.e., 1080p) are encoded using the multi-rate scheme as used in Step 1.
- Repeat Step 2 for the remaining resolution tiers in ascending order with respect to the resolution until no more resolution tiers are left (i.e., only for 2160p in our example).
Results
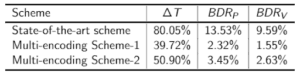
It is observed that the state-of-the-art scheme yields the highest average encoding time-saving, i.e., 80.05%, but it comes with a bitrate increase of 13.53% and 9.59% to maintain the same PSNR and VMAF respectively as compared to the stand-alone encodings. The first proposed multi-encoding scheme has the lowest increase in bitrate to maintain the same PSNR and VMAF (2.32% and 1.55%) respectively as compared to the stand-alone encodings. The second proposed multi-encoding scheme improves the encoding time savings of the first proposed multi-encoding scheme by 11% with a negligible increase in bitrate to maintain the same PSNR and VMAF. This result is shown in Table 1, where Delta T represents the overall encoding time-savings compared to the stand-alone encodings, BDR_P and BDR_V refer to the average difference in bitrate with respect to stand-alone encodings to maintain the same PSNR and VMAF, respectively.
View the full multi-encoding research paper from ATHENA here.
If you liked this article, check out some of our other great ATHENA content at the following links: